Cẩm nang System Design: Xây dựng Hệ thống Phân tán, Microservices và Caching từ Thực tế
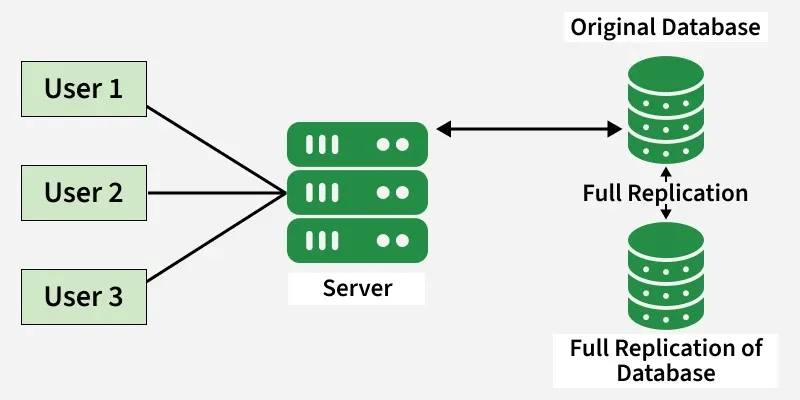
Trong kỷ nguyên số hiện nay, việc thiết kế một hệ thống phần mềm có khả năng mở rộng tốt (scalable), tính sẵn sàng cao (High Availability - HA) và hiệu năng tối ưu luôn là cái đích hướng tới của mọi kỹ sư phần mềm. Dưới đây là những tổng hợp chuyên sâu từ thực tế thiết kế hệ thống phân tán, đi từ các thành phần web cơ bản, bản chất luồng bất đồng bộ của Node.js, cho tới chiến lược Replication dữ liệu, Caching bảo vệ database và lộ trình chuyển đổi từ Monolith sang Microservices với sự trợ lực từ Apache Kafka.
1. Mô hình kiến trúc một hệ thống web cơ bản và hiện đại
Một ứng dụng web quy mô lớn không đơn thuần chỉ là sự kết nối giữa Frontend và Backend. Để đảm bảo tính tin cậy và khả năng chịu tải, hệ thống cần được chia thành nhiều phân lớp chức năng rõ rệt:
- Load Balancer (Nginx, HAProxy, AWS ALB): Là chốt chặn đầu tiên đón nhận traffic từ người dùng, phân phối tải đồng đều đến cụm ứng dụng (Application cluster) phía sau, tránh tình trạng điểm nghẽn đơn lẻ (Single Point of Failure - SPOF).
- API Gateway (Kong, Express Gateway): Đóng vai trò là cửa ngõ duy nhất của hệ thống, xử lý định tuyến (routing), bảo mật xác thực (Authentication), phân quyền (Authorization) và kiểm soát tần suất cuộc gọi (Rate Limiting).
- Database (SQL & NoSQL): Phân chia dữ liệu theo mục đích sử dụng. Dữ liệu giao dịch có cấu trúc chặt chẽ (ACID) dùng PostgreSQL/MySQL; dữ liệu dạng tài liệu, bán cấu trúc cần mở rộng nhanh dùng MongoDB/Cassandra.
- Cache Layer (Redis, Memcached): Lá chắn đắc lực bảo vệ Database khỏi các truy vấn lặp đi lặp lại có độ trễ lớn.
- Background Workers & Task Queue (RabbitMQ, BullMQ, Celery): Xử lý bất đồng bộ các tác vụ tốn thời gian như gửi email, xử lý ảnh, tạo báo cáo... giúp giải phóng tài nguyên cho luồng request chính của người dùng.
2. Khai phá bản chất bất đồng bộ của Node.js
Node.js là một runtime môi trường cực kỳ mạnh mẽ, tuy nhiên vẫn có nhiều hiểu lầm xung quanh cơ chế hoạt động của nó. Node.js sử dụng mô hình Single-threaded Event Loop nhưng lại có khả năng chịu tải hàng vạn kết nối đồng thời. Bản chất của điều kỳ diệu này nằm ở:
- V8 Engine & libuv: V8 (do Google phát triển) biên dịch và thực thi JavaScript trực tiếp sang mã máy. Trong khi đó,
libuv(thư viện viết bằng C++) cung cấp hệ thống Thread Pool (mặc định 4 threads) để xử lý các tác vụ I/O bất đồng bộ ở tầng hệ điều hành. - Event Loop Phases: Bao gồm các giai đoạn như timers (setTimeout), pending callbacks, poll (đọc file, gọi network), check (setImmediate) và close callbacks.
Quy tắc vàng: Node.js cực kỳ phù hợp cho các bài toán I/O-bound (chờ đọc/ghi file, gọi API khác, query database) nhờ cơ chế non-blocking. Ngược lại, đối với các tác vụ CPU-bound (tính toán toán học nặng, mã hóa, render video), luồng chính (Main Thread) sẽ bị block, dẫn tới treo toàn bộ hệ thống. Với các tác vụ này, chúng ta nên cân nhắc sử dụng Worker Threads hoặc chuyển hẳn sang ngôn ngữ như Golang hay C++.

3. Chiến lược sao chép cơ sở dữ liệu (Database Replication)
Khi dữ liệu lớn dần, giải pháp Scale Up (nâng cấp phần cứng máy chủ DB) sẽ chạm ngưỡng giới hạn về vật lý và chi phí. Lúc này, Scale Out thông qua Replication là bắt buộc để đảm bảo High Availability.
3.1. Kịch bản khi Leader Node gặp sự cố
Trong mô hình Active-Passive (Leader-Follower), khi Leader Node đột ngột dừng hoạt động:
- Phát hiện sự cố: Các Follower nhận thấy Leader không gửi phản hồi (heartbeat) trong một khoảng thời gian quy định.
- Bầu cử Leader mới (Leader Election): Các Follower còn lại tiến hành bỏ phiếu thông qua các thuật toán đồng thuận (Raft, Paxos) để chọn ra một node cập nhật nhất lên làm Leader.
- Cấu hình lại hệ thống: Định tuyến lại luồng ghi của client tới Leader mới, đồng thời buộc Leader cũ (nếu sống lại) phải hạ cấp xuống làm Follower.
Thách thức lớn nhất ở đây là hiện tượng Split-Brain (não phân đôi): khi mạng bị phân tách (network partition) khiến hai cụm node đều tự nhận mình là Leader và nhận ghi từ client, dẫn tới xung đột dữ liệu nghiêm trọng.
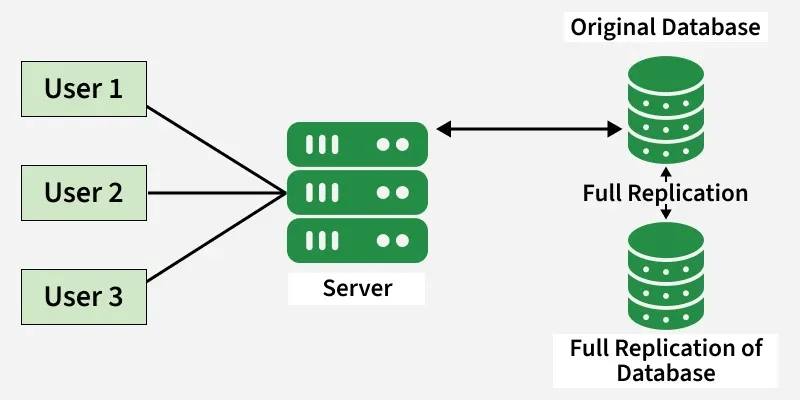
3.2. Sự đánh đổi giữa Consistency và Performance (Sync vs Async Replication)
Synchronous Replication: Leader chỉ xác nhận ghi thành công với Client sau khi toàn bộ Follower đã nhận được dữ liệu.
Ưu điểm: Không mất dữ liệu, tính nhất quán (Consistency) tuyệt đối.
Nhược điểm: Gặp độ trễ lớn (chờ mạng), nếu một Follower chết thì luồng ghi sẽ bị nghẽn.
Asynchronous Replication: Leader xác nhận ghi thành công ngay lập tức với Client, sau đó mới gửi dữ liệu cho Follower qua background process.
Ưu điểm: Tốc độ ghi cực nhanh, chịu lỗi tốt.
Nhược điểm: Nếu Leader chết trước khi dữ liệu kịp truyền đi, dữ liệu đó sẽ biến mất vĩnh viễn.
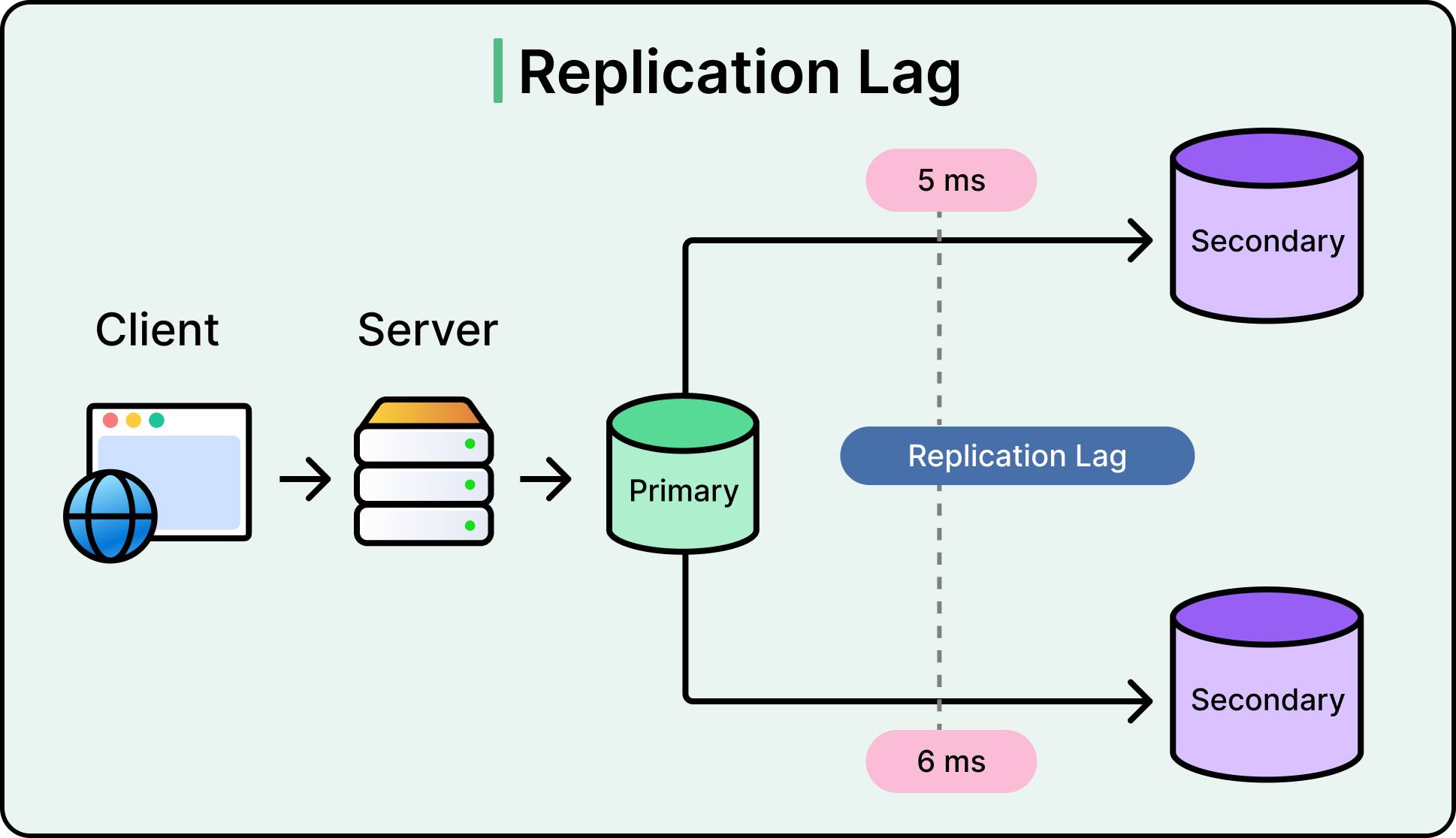
3.3. Hiện tượng Replication Lag và các chuẩn nhất quán cần nhớ
Với cơ chế bất đồng bộ, luôn có một khoảng trễ thời gian (Replication Lag) giữa Leader và Follower. Để tránh trải nghiệm người dùng tệ hại, kỹ sư cần thiết kế các mô hình nhất quán sau:
- Read-Your-Own-Writes Consistency: Đảm bảo người dùng luôn đọc được dữ liệu do chính họ vừa cập nhật (ví dụ: vừa sửa profile thì F5 phải thấy profile mới). Giải pháp: Truy vấn thẳng tới Leader Node khi người dùng vừa thực hiện hành động ghi trong khoảng X giây đầu tiên.
- Monotonic Reads: Tránh hiện tượng "nhảy ngược thời gian". Ví dụ: Client đọc từ Follower A (đã sync) thấy bài viết mới, nhưng lần sau đọc trúng Follower B (chưa sync) lại thấy bài viết biến mất. Giải pháp: Gắn kết định tuyến (sticky routing) của một Client luôn đọc từ một node duy nhất.
- Consistent Prefix Reads: Đảm bảo thứ tự xuất hiện của các dữ liệu luôn đúng logic tuần tự (nguyên nhân - kết quả).
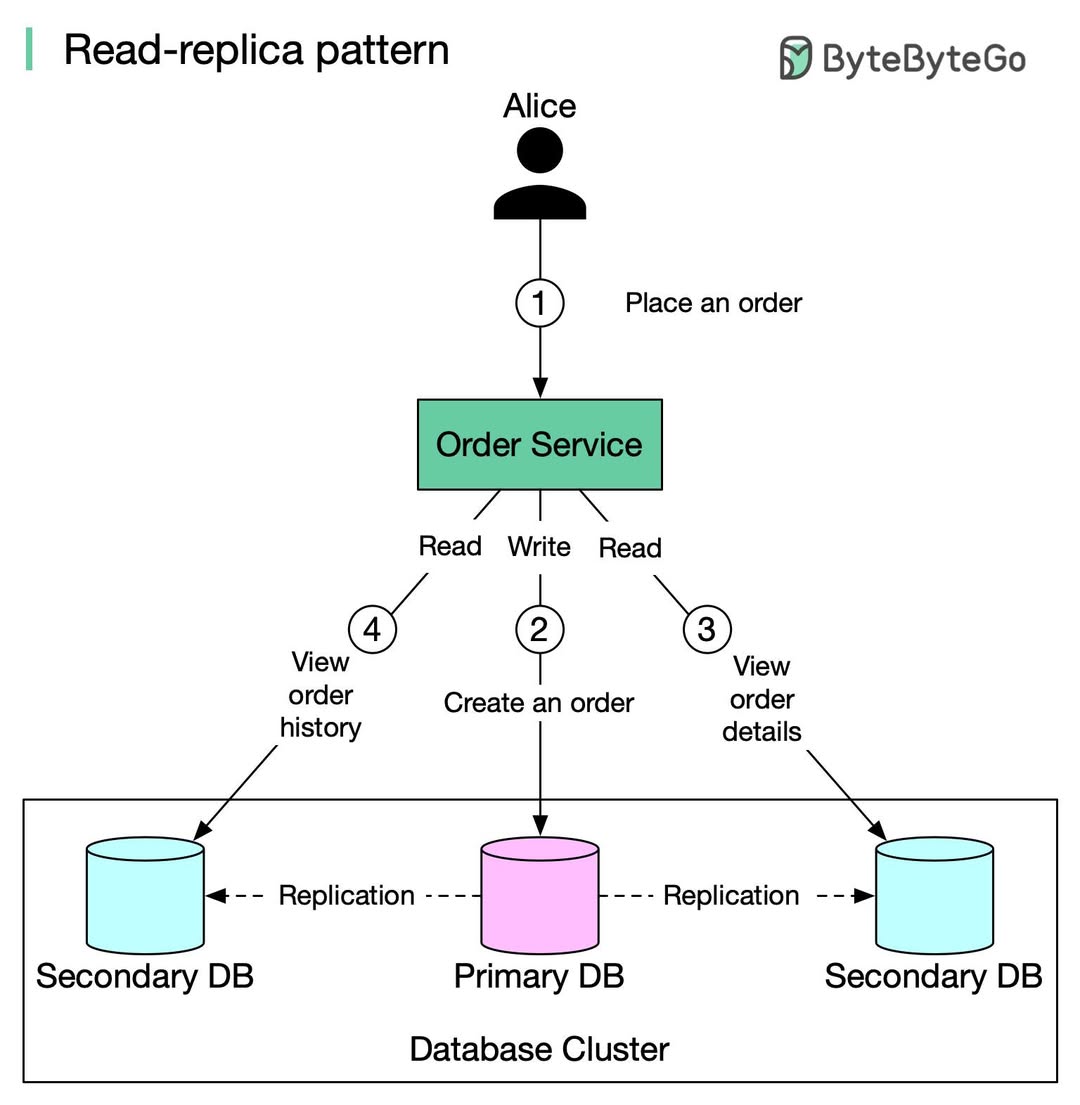
4. Caching - Tối ưu hóa hiệu năng với Redis
Sử dụng Cache (như Redis) là giải pháp nhanh nhất để giảm tải cho DB và cải thiện Latency. Tuy nhiên, quản lý Cache đòi hỏi sự am hiểu sâu sắc về các mô hình thiết kế:
- Cache-Aside (Lazy Loading): App kiểm tra dữ liệu ở Cache trước. Nếu có (cache hit), trả về ngay. Nếu không (cache miss), app query DB, trả về cho người dùng và lưu đệm lại vào Cache. Đây là pattern phổ biến nhất.
- Cache Stampede (Thundering Herd): Xảy ra khi một key rất hot (ví dụ: trang chủ của một KOL) đột ngột hết hạn (expired). Hàng vạn request đồng thời đổ dồn xuống DB để tính toán lại giá trị, làm sập DB ngay lập tức. Giải pháp: Sử dụng khóa phân tán (Distributed Lock - Redlock) hoặc tính toán cập nhật trước khi key thực sự hết hạn.
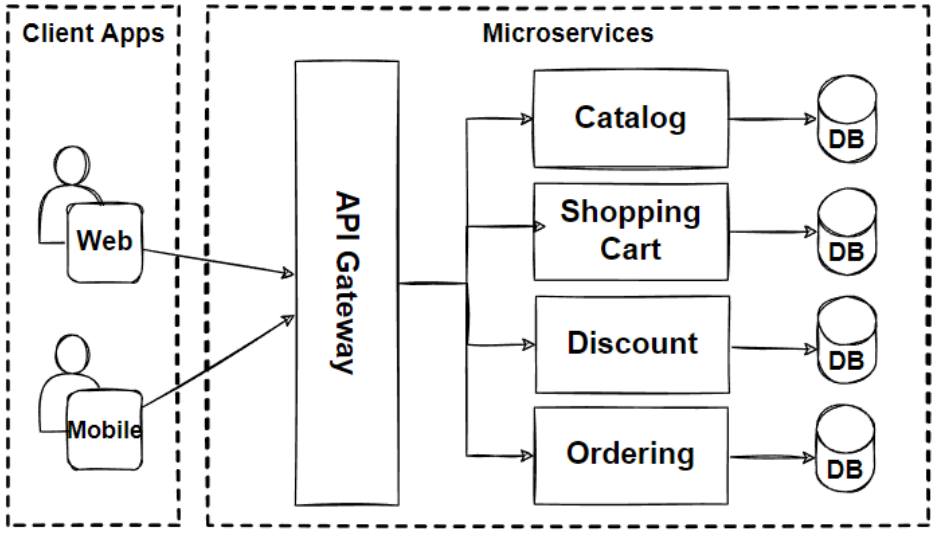
5. Từ Monolith đến Microservices: Khi nào nên chuyển dịch?
Một ứng dụng đặt đồ ăn thời kỳ đầu (MVP) thường được xây dựng theo kiểu Monolith: tất cả module từ Auth, Menu, Order đến Payment đều nằm chung một codebase và chạy chung một process. Sự lựa chọn này giúp phát triển nhanh, kiểm thử dễ dàng và deploy gọn nhẹ.
Nhưng khi số lượng lập trình viên tăng lên và lượng người dùng bùng nổ, Monolith bộc lộ các hạn chế: tranh chấp code (merge conflict), deploy chậm chạp, và một lỗi nhỏ ở Payment có thể kéo sập toàn bộ ứng dụng. Chuyển đổi sang Microservices giúp giải quyết:
- Mỗi service tự chọn công nghệ phù hợp (ví dụ: Payment dùng Java để bảo mật, Recommendation dùng Python cho AI, I/O dùng Node.js).
- Mở rộng độc lập (Scale độc lập dịch vụ Order trong giờ cao điểm thay vì scale toàn bộ app).
Tuy nhiên, chuyển sang Microservices cũng đi kèm các chi phí đắt đỏ về độ phức tạp vận hành, giám sát phân tán (Distributed Tracing), quản lý giao dịch giữa các service (Saga Pattern) và xử lý độ trễ mạng.
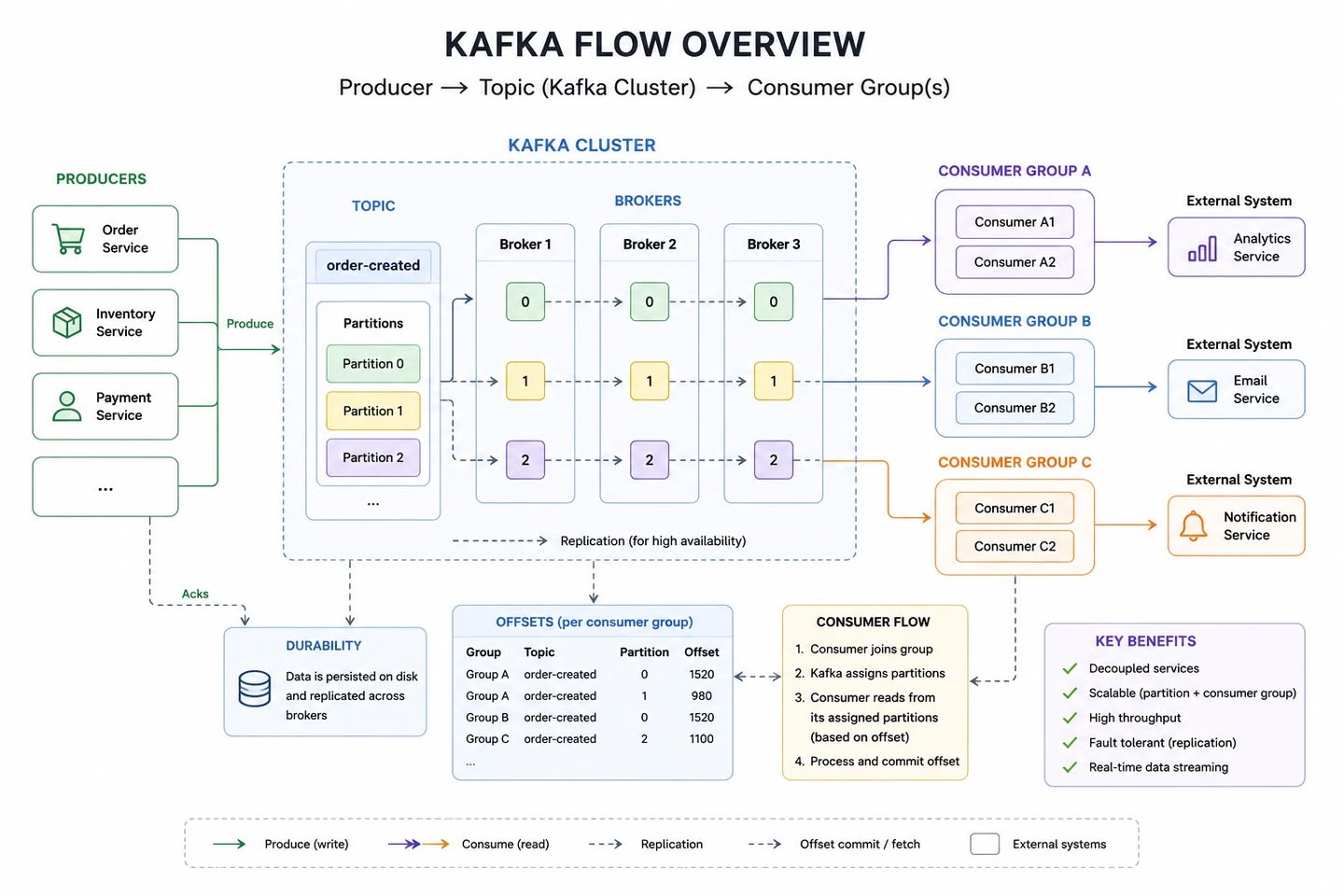
6. Apache Kafka - Xương sống liên kết dịch vụ
Để các Microservices trao đổi dữ liệu hiệu quả mà không làm tăng độ phụ thuộc chặt chẽ (tight coupling), Apache Kafka xuất hiện như một lựa chọn tối ưu.
Khác với Message Broker truyền thống như RabbitMQ (xóa message ngay sau khi tiêu thụ), Kafka là một Distributed Commit Log. Nó lưu trữ message vĩnh viễn trên đĩa cứng dưới dạng chuỗi tuần tự và cho phép nhiều Consumer khác nhau đọc lại (replay) lịch sử bất kỳ lúc nào.
[Producer: Order Service]
│ (Publish: order.created)
▼
┌─────────────┐
│ Kafka Topic │ ── Partitions (0, 1, 2)
└─────────────┘
│ │
│ └──────► [Consumer: Notification Service] (Send SMS)
▼
[Consumer: Payment Service] (Charge money)
Nhờ cấu trúc Partitions và Consumer Groups, Kafka mang lại thông lượng (throughput) cực khủng, là công cụ đắc lực để xử lý dòng sự kiện bất đồng bộ ở các hệ thống tài chính, thương mại điện tử lớn.
Bình luận (0)
Đang tải bình luận...